В чому проблема?#
На одному з фізичних серверів маємо сконфігурований raid1(mdadm) з 2 дисків.
Один з дисків сьогодні вилетів, помер. RAID: State = degraded, а це вже не RAID, тільки raidsolo:).
Потрібно: замінити диск і відновити RAID до стану clean.
На сервері працює Proxmox. (не знаю навіщо ця інформація, взагалі пох, що там працює)
Структура сервера:
| |
Що потрібно зробити?#
- Шукаємо, який конкретно диск мертвий. Це був сервер Dell, тому зробив через iDRAC + підтвердив в терміналі за допомогою
mdadm --detail /dev/md0
| |
| |
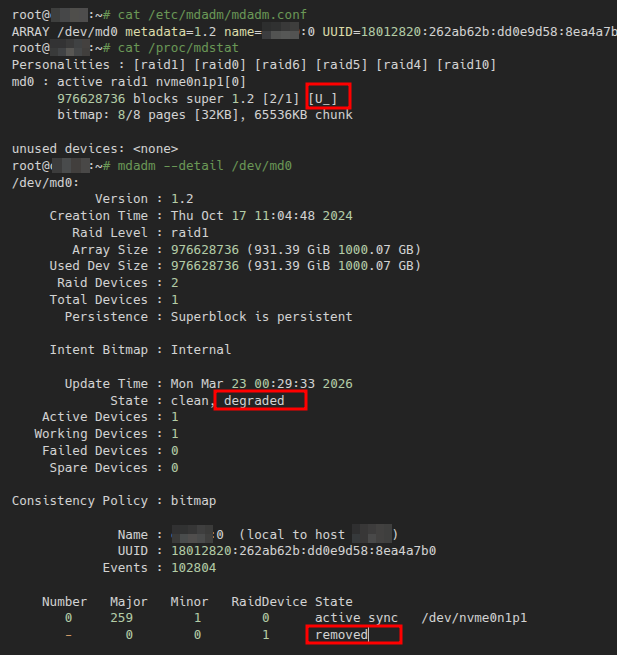
Що бачу:
State: clean, degradedActive Devices: 1[U_]замість[UU]- Один диск
active sync, другий —removed
Масив живий, але летить на одному диску.
Тікет в саппорт DC з проханням замінити фізичний диск. В моєму випадку сервер потрібно було вимкнути повністю (не має доступу до nvme ззовні).
Мабуть непогано було б теж мати бекап , але тоді все буде не так цікаво (+ всі навколо думатимуть, що мою роботу точно не забере AI-шка.)
Чекаю, поки запхають новий диск і відпишуться (і сервер увімк.. увімк… йолка)
Rebuild масиву#
Після того як замінили диск на живий:
Клонуємо таблицю розділів з живого диска на новий:
| |
| |
| |
Додаємо новий диск у масив:#
| |
Перевіряємо прогрес:
| |
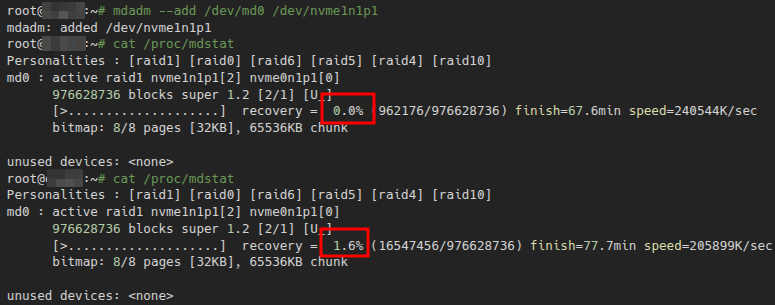
Бачу recovery = 0.0%, потім 1.6%. Rebuild пішов.
В моєму випадку весь процес зайняв близько ~78 хвилин на терабайтний диск.
Сервер працює під час rebuild, але якщо є можливість , то краще не навантажувати.
Після завершення rebuild потрібно оновити конфіг mdamd /etc/mdadm/mdadm.conf
Спочатку видаляємо старий md0. Наприклад за допомогою sed (можна і вручну vim /etc/mdadm/mdadm.conf)
| |
і додаємо актуальний
| |
sed команда >> додасть другий запис про md0. При завантаженні можуть бути проблеми (а мені потрбіний тільки один запис з md0)Проблеми з EFI/GRUB#
У моєму випадку після заміни диска були проблеми із завантаженням системи.
Linux на цьому сервері стоїть на /dev/sda, EFI-партиція - /dev/sda1.
Тому додатково потрібно було виконати ще:
| |
Це не завжди потрібно. Але якщо після ребуту система не стартує — перевіряйте proxmox-boot-tool status.
Повинно писати приблизно таке:
| |
Корисні команди#
Стан масиву
| |
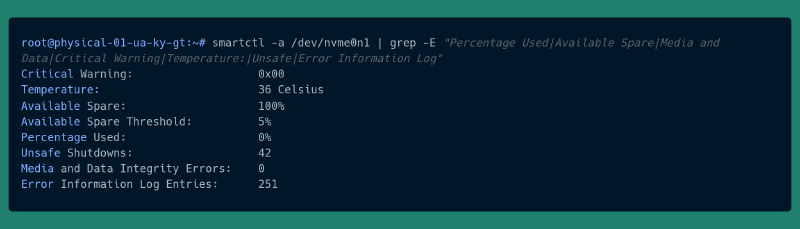
SMART-перевірка диска (побачити проблему ДО а не коли вже гімна повні штани)
| |
SMART-перевірка - а тут конкретно, що тебе повинно цікавити.
| |
Що конкретно моніторити:
- Media and Data Integrity Errors > 0 ===> міняти диск
- Available Spare падає нижче threshold ===> міняти диск
- Percentage Used > 90% ===> Купити диск і планувати його заміну
- Critical Warning != 0x00 ===> а тут вже гайки
Нажми сюди, щоб прочитати що ці параметри означають
Media and Data Integrity Errors - диск записав одне, прочитав інше. Контролер не зміг “порішати”. NAND-чіпи фізично деградують, дані пошкоджуються. Якщо бачиш 1 таку помилка - міняй диск, бо далі буде тільки веселіше.
Available Spare - резервні блоки NAND (запасне колесо в машині) Коли зношується основний блок, контролер підстваляє резервний. Для нас все виглядає ок, бо диск працює, але КОЛИ резервні блоки теж закінчаться (падає нижче threshold) контролеру більше нічим замінювати мертві блоки і посипляться помилки запису.
Аналогія з паливним баком в машині:
- Available Spare - показує скільки в баку
- Available Spare Threshold - червона лампочка на приборці. Далеко не заїдеш.
Percentage Used - ресурс диску (цей диск розрахований на X терабайт запису). Тут як в машині. Гарантія на 100 тисяч км, після - ніби їздить, але кожен місяць у механіка. Якщо дійшов до 90% - купити диск, щоб було чим замінити. Якщо не з такої сімї, а з багатої - одразу міняти при 100%.
Critical Warning - це червоні прапорці. Нам потрібно щоб там завжди було 0x00 - це означає що все добре. Якщо щось інше - гуглить і розбиратись одразу. Бо тут вже лоторея.